
La traducción literal es aprendizaje profundo, pero este concepto —una subcategoría del aprendizaje automático y del universo más amplio de la inteligencia artificial— abarca mucho más que una simple automatización en varios niveles. Por eso, conviene entender de qué se trata el deep learning, cómo funciona y para qué se lo puede usar.
Índice de temas
¿Qué es el Deep Learning?
El deep learning —o aprendizaje profundo— es una rama avanzada del aprendizaje automático que permite a las máquinas analizar datos de forma jerárquica para resolver tareas complejas como el reconocimiento de voz, la visión por computadora o el procesamiento de lenguaje natural. En el ámbito empresarial, esta tecnología se aplica en áreas clave como la automatización, el análisis predictivo y la generación de contenido, con resultados cada vez más precisos y autónomos.
- El deep learning, o aprendizaje profundo, es una subcategoría del machine learning —que significa literalmente aprendizaje de las máquinas— y se refiere a una rama de la inteligencia artificial vinculada a algoritmos inspirados en la estructura y el funcionamiento del cerebro. Estos algoritmos se conocen como redes neuronales artificiales convolucionales.
- Este tipo de aprendizaje se basa en el uso de datos y modelos estadísticos para entrenar máquinas.
- El Deep Learning, también llamado aprendizaje jerárquico o estructurado, forma parte de un conjunto más amplio de métodos de aprendizaje automático que se enfocan en la asimilación de representaciones de datos. A diferencia de otros algoritmos que ejecutan tareas puntuales, estos sistemas aprenden a interpretar y estructurar la información.
- Las arquitecturas de deep learning se usan en tareas como la visión por computadora, el reconocimiento de voz, el procesamiento del lenguaje natural y la bioinformática.
- Según la Universidad de Michigan, el deep learning se diferencia de los enfoques tradicionales de aprendizaje automático en que no requiere una ingeniería de características manual intensiva; en su lugar, las representaciones se aprenden directamente de los datos.
Definiciones del Deep Learning
- McKinsey & Company lo describe como “una versión más avanzada del aprendizaje automático que es particularmente hábil en procesar una gama más amplia de recursos de datos (texto, así como datos no estructurados, incluidas imágenes), requiere incluso menos intervención humana y, a menudo, puede producir resultados más precisos que el aprendizaje automático tradicional”.
- Gartner define el deep learning como “una variante de los algoritmos de aprendizaje automático que utiliza múltiples capas para resolver problemas extrayendo conocimiento de datos sin procesar y transformándolo en cada nivel”.
El Deep Learning según investigadores y científicos
Según interpretaciones de investigadores y científicos destacados en el campo del aprendizaje profundo, como Andrew Yan-Tak Ng, Ian J. Goodfellow, Yoshua Bengio, Ilya Sutskever y Geoffrey Everest Hinton, el Deep Learning se define como un sistema que emplea algoritmos de aprendizaje automático con estas características:
- Utiliza varios niveles de unidades no lineales dispuestas en cascada para tareas de extracción y transformación de características. Cada nivel siguiente toma como entrada la salida del nivel anterior. Los algoritmos pueden ser supervisados o no supervisados. Sus usos incluyen el análisis de patrones —cuando no hay supervisión— y la clasificación —cuando sí la hay—.
- Se apoya en el aprendizaje no supervisado de múltiples niveles jerárquicos de características y representaciones de los datos. Las características de nivel superior se desprenden de las de nivel inferior para construir una estructura jerárquica.
- Forma parte del conjunto más amplio de algoritmos que permiten aprender representaciones de los datos dentro del aprendizaje automático.
- Aprende distintos niveles de representación que reflejan diversos niveles de abstracción, y esos niveles constituyen una jerarquía de conceptos.

Origen del aprendizaje profundo
El aprendizaje profundo tiene sus raíces en las primeras investigaciones sobre redes neuronales que surgieron en las décadas del 40 y del 50. Recién en los años 80 se produjo un avance importante con la introducción del algoritmo de retropropagación, que permitió entrenar redes con múltiples capas.
A partir de ese momento, el desarrollo del aprendizaje profundo avanzó con fuerza gracias a nuevas arquitecturas, algoritmos y mejoras en la capacidad de procesamiento.
En los últimos años, creció de forma acelerada por la disponibilidad de grandes volúmenes de datos, mejoras técnicas y el desarrollo de la tecnología de GPU.
Datos del mercado del Deep Learning
- El mercado global de aprendizaje profundo fue valuado en US$ 7.280 millones en 2024 y proyectan que llegue a US$ 77.910 millones en 2032. Entre 2025 y 2032, crecería a una tasa anual compuesta del 34,5%. Datos de tendencias de inteligencia artificial en Argentina según Data Bridge Market Research.
Para llegar a estas conclusiones, la consultora dividió el mercado global de aprendizaje profundo en distintas categorías para su último informe con proyecciones hasta 2032. La segmentación se organizó en función de cinco ejes: hardware, software, servicios, aplicación y usuario final.

- Ademas, desde Data Bridge Market Research remarcan que el aprendizaje profundo se usa de forma extendida en el procesamiento del lenguaje natural (PLN), en software de reconocimiento de voz, servicios de traducción de idiomas, herramientas de reconocimiento de imágenes y otras utilidades similares.
- Asimismo, señalan que estos desarrollos resultan especialmente útiles en sectores como la salud, la agricultura, la industria manufacturera, el comercio minorista, el automotor y la seguridad.

Según Global Markets Insight, , el crecimiento del aprendizaje profundo se explica por:
- Más inversiones, tanto públicas como privadas, orientadas a su aplicación en diversas industrias.
- Avances tecnológicos que permiten mejorar su rendimiento y ampliar su alcance.
- Demanda en aumento de soluciones basadas en inteligencia artificial por parte de empresas de distintos sectores.
- Respaldo estatal, con gobiernos que impulsan iniciativas para fomentar su desarrollo.
Cómo el Deep Learning impulsa las IA conversacionales como ChatGPT, Bing AI y DeepSeek
Esta tecnología es la base sobre la cual se desarrollan las IA conversacionales más avanzadas de la actualidad, como ChatGPT, Bing AI y DeepSeek, y marca también el camino hacia el desarrollo de modelos de inteligencia artificial general.
Gracias al deep learning, estos modelos pueden comprender el lenguaje natural, generar respuestas coherentes y adaptarse al contexto de cada conversación. No se limitan a responder preguntas preprogramadas, sino que aprenden de patrones complejos en millones de ejemplos para ofrecer respuestas cada vez más precisas, humanas y útiles.
ChatGPT, por ejemplo, está entrenado con grandes cantidades de texto para simular diálogos realistas, mientras que Bing AI integra capacidades de búsqueda y generación de contenido en tiempo real. DeepSeek, por su parte, aplica modelos multimodales para interpretar distintos formatos de entrada (texto, imagen, audio) en sus interacciones.
Ejemplos de usos reales
- Reconocimiento de imágenes: el aprendizaje profundo se aplica en sistemas de visión computarizada para identificar objetos, rostros, señales de tránsito, entre otros elementos visuales.
- Traducción automática: los sistemas actuales de traducción online incorporan modelos basados en aprendizaje profundo para lograr traducciones más precisas y con mejor fluidez entre distintos idiomas.
- Reconocimiento de voz: los asistentes virtuales y otros sistemas que interpretan la voz humana funcionan con redes neuronales profundas, que les permiten comprender y responder a comandos hablados.
- Análisis de sentimientos: esta tecnología se usa para interpretar opiniones y emociones en textos. A partir de eso, clasifica comentarios según su tono: positivo, negativo o neutral.
- Conducción autónoma: los vehículos que manejan sin intervención humana dependen de algoritmos de aprendizaje profundo para reaccionar ante situaciones reales del tránsito, como la detección de peatones, señales y obstáculos.
- Generación de contenido: El aprendizaje profundo se utiliza para generar contenido como imágenes, música y texto de manera automatizada, como en la creación de arte generativo (con IA generativa) o la redacción automática de noticias.
- Recomendación de productos: Las plataformas de comercio electrónico usan algoritmos de deep learning para ofrecer recomendaciones personalizadas según el historial de compras y las preferencias de cada usuario.
- Medicina y diagnóstico: La inteligencia artificial se aplica en el diagnóstico de enfermedades, el análisis de imágenes médicas y la identificación de patrones en datos clínicos.
- Procesamiento de lenguaje natural en empresas: Los sistemas que trabajan con lenguaje natural emplean modelos de aprendizaje profundo para comprender y generar texto con mayor precisión, como ocurre en los chatbots o los sistemas de respuesta automática.
- Análisis de datos y detección de fraudes: El aprendizaje profundo permite analizar grandes volúmenes de datos e identificar patrones anómalos que puedan señalar fraudes, intrusiones o comportamientos poco habituales.
- Simulación y predicción de estructuras moleculares: En biotecnología y farmacología, modelos como AlphaFold, de DeepMind, usan redes neuronales profundas para predecir con precisión la estructura tridimensional de proteínas. Este avance acelera la investigación médica y el desarrollo de nuevos medicamentos.
- Modelado del comportamiento del consumidor en tiempo real: Plataformas de marketing digital y comercio online aplican deep learning para generar recomendaciones y anticipar comportamientos en tiempo real, como el abandono del carrito o posibles clics. A partir de eso, activan automatizaciones personalizadas.
- Restauración y mejora de imágenes o videos antiguos: Los modelos de superresolución y restauración basados en deep learning mejoran la calidad de imágenes borrosas, antiguas o con ruido. Incluso permiten colorizar fotos en blanco y negro de manera automática.
- Creación de avatares realistas y animaciones faciales: Empresas como Meta, NVIDIA y algunas startups de realidad aumentada desarrollaron tecnologías que generan avatares digitales capaces de imitar expresiones humanas en tiempo real. Estas herramientas ya se usan en videojuegos, entornos virtuales y atención al cliente con humanos digitales.
- Predicción de eventos climáticos extremos: Redes neuronales profundas entrenadas con datos meteorológicos históricos ayudan a prever tormentas, huracanes o sequías con mayor anticipación y precisión que los modelos tradicionales.
- Optimización del consumo energético: En ciudades inteligentes y edificios inteligentes, se usa deep learning para predecir el uso energético y optimizar el consumo según patrones de comportamiento, clima, y horarios.
Las redes neuronales artificiales son la base del aprendizaje profundo
En el aprendizaje profundo, igual que en el cerebro humano, se seleccionan y clasifican datos relevantes para llegar a conclusiones.
Las redes neuronales profundas son modelos matemáticos y computacionales inspirados en las redes neuronales biológicas.. Estas redes adaptativas modifican su estructura a partir de datos externos e internos, lo que permite que aprendan y razonen.
Componentes del aprendizaje profundo
- Redes neuronales artificiales: Son la base del aprendizaje profundo. Estas redes están compuestas por capas de neuronas interconectadas que procesan y transmiten información.
- Capas ocultas: Son las capas intermedias entre la capa de entrada y la capa de salida en una red neuronal profunda. Estas capas permiten la extracción de características y la creación de niveles de abstracción más altos.
- Algoritmos de retropropagación: Son utilizados para ajustar los pesos y las conexiones de las neuronas en la red neuronal durante el entrenamiento. La retropropagación permite la corrección de errores y el refinamiento de los resultados.
- Funciones de activación: Son aplicadas en cada neurona para introducir la no linealidad en la red neuronal. Ejemplos comunes de funciones de activación son la función sigmoide, la función ReLU (Rectified Linear Unit) y la función tangente hiperbólica.
- Conjunto de datos de entrenamiento: Es un conjunto de ejemplos de entrada y sus correspondientes etiquetas utilizados para entrenar la red neuronal. Estos datos permiten que la red aprenda y ajuste sus parámetros.
- Función de pérdida: Es una medida utilizada para evaluar la discrepancia entre las salidas predichas por la red neuronal y las salidas deseadas. La función de pérdida guía el proceso de optimización durante el entrenamiento.
- Optimización y actualización de pesos: Se refiere al proceso de ajustar los pesos y las conexiones de la red neuronal para minimizar la función de pérdida. Esto se logra mediante algoritmos de optimización, como el descenso de gradiente estocástico (SGD) y sus variantes.
Cómo funciona el Deep Learning
El funcionamiento del aprendizaje profundo se puede entender de la siguiente manera, y se complementa en algunos casos con métodos de árbol de decisión:
- Entrada de datos: Se proporcionan datos de entrada al sistema, como imágenes, texto o sonidos.
- Capas ocultas: Los datos pasan a través de múltiples capas ocultas de neuronas, que realizan cálculos y transformaciones en los datos.
- Ponderación y activación: Cada conexión entre las neuronas tiene un peso asignado, que determina la importancia de esa conexión. Las neuronas aplican una función de activación para determinar si deben activarse o no.
- Aprendizaje mediante retroalimentación: Durante la fase de entrenamiento, se ajustan los pesos de las conexiones en base a la retroalimentación recibida, con el objetivo de minimizar el error entre las salidas esperadas y las salidas obtenidas.
- Predicción y clasificación: Una vez que el modelo ha sido entrenado, se utiliza para realizar predicciones o clasificar nuevos datos de entrada en categorías o etiquetas relevantes.
- Mejora continua: El modelo puede ser refinado y mejorado mediante iteraciones adicionales de entrenamiento, ajustando los hiperparámetros y optimizando el rendimiento.
- Aplicaciones prácticas: El aprendizaje profundo se utiliza en diversas aplicaciones, como reconocimiento de imágenes, procesamiento del lenguaje natural, conducción autónoma y recomendaciones personalizadas.
Con el deep learning, se simulan los procesos de aprendizaje del cerebro humano a través de sistemas artificiales, como las redes neuronales artificiales. El objetivo es enseñar a las máquinas a aprender de manera autónoma y, además, hacerlo de forma más profunda, como lo hace el cerebro humano.
Ese “profunda” hace referencia a la cantidad de niveles que tiene la red, es decir, al número de capas ocultas —también llamadas capas hidrenas— dentro de la red neuronal. Las redes neuronales tradicionales tienen entre dos y tres capas, mientras que las redes profundas pueden superar las 150.
La siguiente imagen (extraída del libro electrónico de acceso gratuito “Neural Networks and Deep Learning“) puede ayudar a comprender mejor la “estructura” de las redes neuronales profundas.
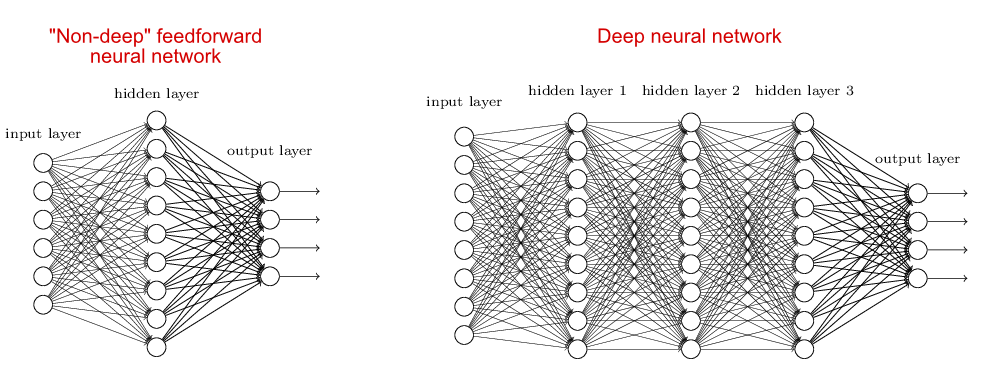
Las redes neuronales profundas usan una mayor cantidad de capas intermedias —también llamadas capas hidráulicas— para construir más niveles de abstracción. Es un funcionamiento similar al de los circuitos booleanos, un modelo matemático de computación utilizado en el estudio de la tipología de inteligencia artificial y complejidad computacional. Esta teoría, en informática, se ocupa de la computabilidad: analiza cuáles son los recursos mínimos necesarios, sobre todo el tiempo de cálculo y la memoria, para resolver un problema.
Un ejemplo concreto del funcionamiento de una red neuronal profunda en el reconocimiento de patrones visuales puede ayudar a entenderlo mejor. Las neuronas de la primera capa detectan bordes. Las de la segunda reconocen formas más complejas, como triángulos o rectángulos, formados a partir de esos bordes. La tercera capa interpreta figuras más elaboradas. La cuarta suma más detalles, y así sucesivamente.
Esa acumulación de niveles intermedios permite que las redes neuronales profundas incorporen más información útil y realicen un análisis progresivo que mejora la calidad de la respuesta final. Por eso pueden resolver problemas complejos de reconocimiento de patrones con mayor precisión.
Es fácil ver que, cuanto mayor sea la cantidad de capas intermedias en una red neuronal profunda —y, por lo tanto, más grande sea la red—, más eficaz puede ser el resultado en la tarea que se le asigna. Sin embargo, la escalabilidad de este tipo de redes depende directamente de los conjuntos de datos, los modelos matemáticos y los recursos computacionales disponibles.
Diferencia entre Deep Learning y Machine Learning
Aunque la necesidad de una enorme capacidad computacional puede representar un límite, lo que distingue al Deep Learning del Machine Learning es su capacidad para escalar gracias al aumento de datos y algoritmos disponibles.
Los sistemas de Deep Learning mejoran su rendimiento a medida que crecen los volúmenes de información. En cambio, los sistemas de Machine Learning —también llamados de aprendizaje superficial—, una vez que alcanzan cierto nivel de precisión, dejan de mejorar, incluso si se les agregan nuevos datos o ejemplos para entrenar la red neuronal.
La diferencia principal está en cómo se identifican y procesan las características. En el Machine Learning, por ejemplo en sistemas de reconocimiento visual, las características de un objeto se extraen y seleccionan de forma manual. Con eso se construye un modelo que luego clasifica y reconoce objetos según esas características.
En el Deep Learning, en cambio, la red neuronal aprende de manera autónoma a partir de los datos en bruto. Es decir, descubre por sí sola qué rasgos analizar y cómo resolver una tarea, como clasificar un objeto.
Si bien desde el costado de la potencialidad el Deep Learning puede parecer más atractivo y útil que el Machine Learning, hay que señalar que el cálculo computacional necesario para hacerlo funcionar es realmente elevado, también en términos económicos. Las CPUs más avanzadas y las GPUs de alta gama, necesarias para sostener las cargas de trabajo de un sistema de Deep Learning, todavía cuestan varios miles de dólares.
Usar capacidad computacional a través de la nube sólo alivia el problema de forma parcial. Entrenar una red neuronal profunda exige procesar grandes volúmenes de datos con clusters de GPUs potentes durante muchas horas. Por eso, acceder a esa capacidad “como servicio” no garantiza que el costo sea accesible.
Comparativa: Deep Learning vs. Machine Learning
| Aspecto | Machine Learning | Deep Learning |
|---|---|---|
| Mejora con más datos | Llega a un punto de saturación: agregar más datos no mejora el rendimiento. | Escala con grandes volúmenes de datos: mejora su rendimiento cuanto más datos procesa. |
| Extracción de características | Manual: las características deben ser seleccionadas y extraídas por humanos. | Automática: la red neuronal aprende qué características analizar directamente de los datos en bruto. |
| Dependencia computacional | Moderada: puede entrenarse en CPUs estándar. | Alta: requiere GPUs de alta gama y gran capacidad computacional. |
| Costo económico | Más accesible: menor necesidad de hardware especializado. | Elevado: las GPUs necesarias cuestan miles de dólares, incluso en esquemas de pago por uso en la nube. |
| Autonomía en el aprendizaje | Limitada: necesita intervención humana en el diseño del modelo. | Alta: aprende de manera autónoma cómo resolver tareas complejas. |
| Aplicaciones comunes | Problemas con conjuntos de datos más pequeños o bien estructurados. | Problemas complejos como reconocimiento de imágenes, voz o procesamiento del lenguaje natural. |
Cómo entrenar un sistema de Deep Learning
Un ejemplo simple pero efectivo para entender cómo funciona un sistema de Machine Learning, y en qué se diferencia de uno de Deep Learning, lo aporta TechTarget.
Mientras que los algoritmos tradicionales de aprendizaje automático siguen una lógica lineal, los de aprendizaje profundo se estructuran en una jerarquía donde cada nivel incorpora mayor complejidad y abstracción.
Deep Learning explicado con un ejemplo cotidiano
Para ilustrarlo, se puede pensar en un nene que dice su primera palabra: “perro”. Aprende qué es un perro y qué no lo es al señalar objetos y decir “perro”. El padre le responde: “Sí, eso es un perro” o “No, eso no es un perro”. Con el tiempo, el chico empieza a identificar qué rasgos tienen en común todos los perros.
Sin saberlo, construye una abstracción compleja —el concepto de “perro”— formando una jerarquía donde cada nivel se apoya en lo aprendido previamente. Así funciona el Deep Learning: cada capa de la red analiza la información con mayor profundidad gracias a lo que recogió la capa anterior.
Velocidad y autonomía de los sistemas de Deep Learning
A diferencia del nene, que necesita semanas o incluso meses para entender qué es un “perro” y lo hace con la ayuda de sus padres —es decir, mediante aprendizaje supervisado—, una aplicación que usa algoritmos de Deep Learning puede analizar y organizar millones de imágenes en pocos minutos. Lo hace con precisión, incluso sin recibir indicaciones sobre si la identificación de ciertas imágenes durante el entrenamiento fue correcta o no.
Cómo aprende un modelo de Deep Learning
En general, en los sistemas de Deep Learning, la única intervención de los científicos consiste en etiquetar los datos con metaetiquetas. Por ejemplo, asignan la metaetiqueta “perro” a las imágenes donde aparece un perro, pero sin decirle al sistema cómo reconocerlo. Es la red, a través de sus múltiples niveles jerárquicos, la que deduce por sí sola qué elementos definen a un perro —las patas, el hocico, el pelo, entre otros rasgos— y, por lo tanto, cómo identificarlo.
Limitaciones y desafíos del entrenamiento en Deep Learning
Estos sistemas funcionan, en esencia, a través de un proceso de aprendizaje por prueba y error, pero para que el resultado sea confiable necesitan volúmenes enormes de datos.
Ahora bien, suponer que el Big Data y la facilidad con la que hoy se generan y distribuyen datos de todo tipo resuelven el problema sería un error. Para lograr precisión en los resultados, al menos en la etapa inicial de entrenamiento, es necesario usar datos etiquetados, es decir, aquellos que contienen metaetiquetas.
Por eso, los datos no estructurados pueden representar un obstáculo. Un modelo de Deep Learning puede analizarlos una vez que ya fue entrenado y alcanzó un nivel de precisión aceptable, pero no sirven para entrenarlo desde cero.
Además, los sistemas basados en Deep Learning presentan una gran dificultad en su etapa de entrenamiento por la cantidad de capas que conforman la red neuronal. El número de capas y las conexiones entre las neuronas pueden ser tan altos que se vuelve complejo calcular los ajustes necesarios en cada fase del proceso. Este inconveniente se conoce como desaparición del gradiente.
El entrenamiento suele realizarse con algoritmos de retropropagación del error, que ajustan los pesos de la red —es decir, las conexiones entre neuronas— cada vez que se detecta un error. La red propaga ese error hacia atrás para modificar los pesos y mejorar la precisión. Este proceso se repite de manera iterativa hasta que el gradiente, que indica en qué dirección debe avanzar el algoritmo, se vuelve nulo.
Frameworks para Deep Learning: TensorFlow y PyTorch
Uno de los frameworks más usados para Deep Learning entre investigadores, desarrolladores y científicos de datos es TensorFlow.. Se trata de una librería de software de código abierto impulsada por Google, que ofrece módulos probados y optimizados para implementar algoritmos en distintos tipos de software y lenguajes de programación. Funciona con Python, C/C++, Java, Go, RUST y R, entre otros, y resulta especialmente útil para tareas relacionadas con la percepción y la comprensión del lenguaje natural.
En 2019 empezó a tomar fuerza otro framework que, según algunos analistas como Janakiram MSV en un artículo publicado en Forbes, “se está convirtiendo rápidamente en el favorito de los desarrolladores y científicos de datos”. Se trata de PyTorch, un proyecto de código abierto desarrollado por Facebook, que ya forma parte de los procesos internos de la empresa.
Durante varios años, los desarrolladores de Facebook trabajaron con un framework conocido como Caffe2, que también tuvo adopción en distintas universidades y entre investigadores. Pero en 2018, la empresa anunció que desarrollaba una nueva herramienta a partir del trabajo hecho con Caffe2, con la intención de lanzar un framework accesible para la comunidad de código abierto.
En realidad, Facebook buscó combinar lo mejor de Caffe2 y ONNX en un nuevo framework: PyTorch. ONNX, sigla de Open Neural Network Exchange, es un proyecto interoperable al que Microsoft y AWS también aportan activamente, al brindar soporte para Microsoft CNTK y Apache MXNet.
PyTorch 1.0 logró combinar lo mejor de Caffe2 y ONNX, y se convirtió en uno de los primeros frameworks con soporte nativo para modelos ONNX.
El objetivo de los desarrolladores de Facebook (y también de otros actores del sector) es construir un framework más simple y accesible que TensorFlow. PyTorch, por ejemplo, utiliza una técnica llamada cálculo dinámico, que facilita el entrenamiento de redes neuronales.
Pero no es lo único. “El modelo de ejecución de PyTorch imita el modelo de programación convencional que conoce un desarrollador medio de Python. También ofrece formación distribuida, una profunda integración en Python y un vibrante ecosistema de herramientas y bibliotecas, lo que lo hace popular entre investigadores e ingenieros”, escribió el analista Janakiram MSV en su artículo.
Tendencias del mercado de aprendizaje profundo, según Global Markets Insight
- Los algoritmos y el poder de cálculo avanzaron de forma sostenida, lo que potenció las capacidades de los modelos de aprendizaje profundo y los volvió más eficaces y precisos.
- Innovaciones como las redes neuronales convolutivas (CNN) y las redes neuronales recurrentes (RNN) mejoraron el rendimiento en tareas de reconocimiento de imagen y habla, procesamiento de lenguaje natural y sistemas autónomos.
- Los modelos actuales son más profundos y complejos, lo que les permite aprender con mayor eficacia a partir de conjuntos masivos de datos. Esto incrementa la precisión y la confiabilidad.
- El desarrollo de hardware especializado, como las GPUs y TPUs, facilitó el entrenamiento de estos modelos con mayor rapidez y a gran escala.La adopción de soluciones inteligentes por parte de las industrias impulsa la inversión en tecnologías de inteligencia artificial vinculadas al aprendizaje profundo.El avance tecnológico acelera la implementación de estas herramientas en múltiples sectores y abre nuevas posibilidades para su uso.
¿Cuáles son las limitaciones para el crecimiento del Deep Learning?
- La privacidad de los datos representa una traba para el crecimiento del mercado.
- El aprendizaje profundo requiere grandes volúmenes de información, muchas veces sensible, lo que genera preocupación por el modo en que se recopila, almacena y utiliza.
- Regulaciones estrictas, como el GDPR en Europa, aumentaron la presión sobre las empresas en relación con el tratamiento de datos personales.
- Las compañías deben ajustarse a marcos legales complejos, lo que puede limitar su capacidad para entrenar modelos sin restricciones.
- Esto frena la adopción de la tecnología, sobre todo en organizaciones que priorizan la confianza del usuario y el respeto por criterios éticos.
FAQs: Preguntas frecuentes sobre Deep Learning en 2025
¿Qué factores deben considerarse al elegir entre TensorFlow y PyTorch en un entorno corporativo?
La elección depende del nivel de integración requerido, escalabilidad y curva de aprendizaje del equipo. PyTorch ofrece mayor flexibilidad en investigación, mientras TensorFlow es preferido en entornos productivos por su robustez y compatibilidad con sistemas empresariales.
¿Cómo puede una empresa integrar modelos de Deep Learning en su arquitectura de TI existente?
La integración se facilita mediante APIs RESTful, contenedores Docker y orquestadores como Kubernetes. Estas herramientas permiten desplegar modelos en la nube o en edge computing, asegurando escalabilidad y continuidad operativa.
¿Qué riesgos de ciberseguridad están asociados con la implementación de modelos de Deep Learning?
Los riesgos incluyen ataques adversariales, fuga de datos sensibles durante el entrenamiento y manipulación de modelos. Es clave aplicar técnicas de robustez algorítmica y cumplimiento normativo como ISO/IEC 27001.
¿Cuáles son las mejores prácticas para escalar modelos de aprendizaje profundo de la etapa experimental a producción?
Implica usar pipelines de MLOps, versionado de modelos, monitoreo de rendimiento y validación continua. Frameworks como MLflow y Kubeflow permiten automatizar este proceso y reducir el time-to-market.





