
Una de las ventajas más claras que trajo la tecnología de la información es la posibilidad de analizar, estudiar, relacionar y compartir datos heterogéneos y, a simple vista, sin conexión entre sí. Todo con el objetivo de generar nuevos conocimientos y aportar beneficios a las personas, a las empresas y a la comunidad. También sirve para tomar mejores decisiones.
Alcanza con pensar en lo que logró la inteligencia artificial. Hoy, las computadoras y procesadores pueden sumar en tiempo real una cantidad enorme de datos para simular las capacidades cognitivas del cerebro humano. O en la Internet de las Cosas, que permite que personas, objetos y dispositivos electrónicos intercambien información sin interrupciones. Y en los sistemas más recientes, como los autos que se manejan solos, que procesan miles de millones de datos a una velocidad impresionante.
En el centro de esta revolución, que ya cambió la forma en que pensamos, actuamos y nos comunicamos, hay una tecnología que, aunque parezca “vieja” o “madura” en relación con el ritmo vertiginoso de la informática, sigue siendo clave: las bases de datos. Junto con sus sistemas de gestión, conocidos por sus siglas en inglés como DBMS (Data Base Management System).
No hay ningún programa o dispositivo electrónico que no almacene, procese, transforme o vuelva a trabajar datos guardados en estructuras más o menos permanentes. Estas pueden ser plataformas sofisticadas para manejar información, archivos simples, registros o hasta porciones de memoria.
Índice de temas
¿Qué es una base de datos?
Podés pensar una base de datos como un conjunto de datos estructurados. No hace falta que tengan el mismo contenido ni formato, pero están almacenados de forma electrónica y se accede a ellos mediante funciones y servicios digitales.
A simple vista, una base de datos puede parecer una versión digital de los viejos archivos en papel. Es capaz de guardar en pequeños dispositivos electrónicos la misma información que antes ocupaba carpetas enormes, guardadas en estructuras físicas que llegaban a ocupar cientos o miles de metros cuadrados.
Pero en realidad, una base de datos es mucho más que eso. Es una herramienta potente y muy eficaz, que permite hacer análisis, organizar la información y relacionar datos. Estas funciones son la base de casi todas las tecnologías actuales. Además, permiten descubrir patrones o conocimientos nuevos a partir de datos que, por sí solos, parecerían no tener importancia, pero que revelan mucho cuando se los analiza dentro de un conjunto amplio.

Definiciones de base de datos
“Una base de datos es una colección de información organizada y almacenada, diseñada para su búsqueda y recuperación. Las bases de datos vienen en diversos formatos y pueden utilizarse para distintas aplicaciones”. Definición de Universidad Estatal de Columbia del Sur.
“Una base de datos es una colección organizada de datos almacenados en
múltiples conjuntos de datos. Estos conjuntos de datos generalmente se almacenan y se acceden electrónicamente desde un sistema informático que facilita su acceso, manipulación y actualización”. Definición del Servicio Geológico de los Estados Unidos (USGS).
Análisis del mercado de base de datos
Según la consultora Mordor Intelligence:
- El mercado de bases de datos alcanzaría los US$ 292.220 millones para 2030, con una tasa de crecimiento anual (CAGR) del 14,21% entre 2025 y 2030.
- La demanda está evolucionando por la migración de bases de datos locales a soluciones nativas en la nube, impulsada por la necesidad de reducir costos de infraestructura y escalar recursos.
- Amazon Web Services (AWS), Microsoft Azure y Google Cloud lideran la oferta de servicios de bases de datos en la nube, con opciones flexibles y accesibles.
- En junio de 2024, Oracle se colocó como el principal sistema de gestión de bases de datos (DBMS) con un puntaje de 1244,08, seguido por MySQL y Microsoft SQL Server.
- Se destaca el aumento de las bases de datos SQL distribuidas, que combinan el SQL clásico con la escalabilidad de NoSQL. Brindan transacciones ACID, alta disponibilidad y resiliencia en la nube.
- Persiste el desafío del crecimiento del volumen de datos, con tasas anuales del 30% o más, lo que complica la escalabilidad eficiente y la gestión de costos. Esto puede provocar cuellos de botella en el rendimiento y uso ineficiente de recursos.

Por otro lado, Gartner observa un salto importante en el uso de tecnologías gráficas. Según la consultora, “para 2025, estas tecnologías se utilizarán en el 80% de las innovaciones de datos y análisis, lo que facilitará la toma de decisiones rápida en toda la empresa”. En 2021, ese porcentaje apenas alcanzaba el 10%, por lo que el crecimiento proyectado es notable.
Qué son los sistemas de gestión de bases de datos
Los componentes de software conocidos como “Data Base Management System” (DBMS) cumplen un rol clave. Se trata de sistemas informáticos diseñados para crear, manipular, consultar y, en general, gestionar bases de datos de forma ágil y eficaz.
Un DBMS funciona como una capa de software que conecta las apps con los datos. Lo hace mediante herramientas y funciones fáciles de usar, lo que les permite a los operadores —como administradores de sistemas, programadores o analistas— trabajar sin necesidad de lidiar con el “esquema físico”, es decir, la estructura concreta de la base de datos. En su lugar, pueden manejar un “modelo conceptual”, una representación lógica que resulta mucho más sencilla de interpretar y modificar.
Componentes de un DMBS
Desde el punto de vista arquitectónico, un DMBS puede dividirse en tres componentes principales que pueden describirse como sigue:
- El “diccionario de datos“, definido en el “IBM Dictionary of Computing” como un “repositorio centralizado de información sobre los datos, como su significado, su relación con otros datos, su origen, su uso y su formato“. Consiste, esencialmente, en una colección de metadatos que contienen información sobre los datos del repositorio.
- Es un componente de importancia fundamental porque permite interpretar sin ambigüedad la estructura, la finalidad y el valor de los datos contenidos en la base de datos. Puede considerarse como una “tarjeta de visita” de la BD, en la que se resumen las características fundamentales capaces de guiar a los usuarios y a las aplicaciones hacia un uso correcto y consciente de los datos almacenados en el archivo electrónico.
- El “lenguaje de definición de datos“, en cambio, está diseñado para estructurar el contenido de una base de datos mediante, por ejemplo, la creación, modificación o eliminación de definiciones de tablas, usuarios y permisos. A través de este componente, en concreto, se pueden definir los esquemas lógicos que subyacen al funcionamiento de una base de datos (por ejemplo, se puede indicar qué columnas debe tener una tabla) pero no gestionar directamente los datos y, por tanto, los activos de información que gestiona la BD.
- El “lenguaje de manipulación de datos“. Se utiliza, por último, para borrar, insertar, modificar y leer los registros de datos contenidos en una base de datos. Es, por tanto, la capa más operativa, que permite a los usuarios externos poblar la BD de acuerdo con las restricciones definidas en el módulo anterior y obtener la información que necesita cada aplicación individual que accede a la base de datos.
Tabla: Componentes de un DBMS
| Componente | Descripción |
|---|---|
| Diccionario de datos | Repositorio centralizado de metadatos que describe el significado, uso, origen, relaciones y formato de los datos. Actúa como una “tarjeta de visita” de la base de datos, permitiendo una interpretación clara de su contenido. |
| Lenguaje de definición de datos (DDL) | Se utiliza para estructurar la base de datos mediante la creación, modificación o eliminación de elementos como tablas, usuarios y permisos. Define los esquemas lógicos de la base de datos. |
| Lenguaje de manipulación de datos (DML) | Permite insertar, modificar, eliminar y consultar datos en la base de datos. Es la capa operativa mediante la cual los usuarios interactúan con los datos según las reglas definidas previamente. |
Entre las tareas de los DBMS también se pueden mencionar las de asegurar la compartición e integración de datos entre diferentes aplicaciones, controlar el acceso concurrente a la información y garantizar la seguridad e integridad de la información procesada mediante mecanismos de lectura y escritura adecuados.
Sanjeev Mohan, analista principal de SanjMo y exvicepresidente de Gartner:
A medida que los patrimonios de datos se fragmentan y las unidades de negocio financian sus propias soluciones, las empresas necesitan facilitar la portabilidad de sus datos, evitando la dependencia de proveedores y formatos propietarios. Para abordar este desafío.
Además, la integración de inteligencia artificial generativa en los sistemas de bases de datos marcó otro salto importante. Algunos proveedores líderes ya incorporaron modelos de lenguaje avanzados para facilitar consultas semánticas, generar dashboards de forma automática o sugerir estructuras de datos según el uso histórico. Plataformas como Snowflake y Databricks avanzan con funciones que permiten interactuar con grandes volúmenes de datos usando lenguaje natural. Esto acelera la toma de decisiones y abre el acceso a la información.
Estas tendencias muestran que los nuevos sistemas de gestión de bases de datos dejaron de ser simples herramientas de almacenamiento. Ahora funcionan como plataformas capaces de aprender, adaptarse y potenciar el análisis de datos en tiempo real.
Base de datos dinámicas
Estas suelen ser muy utilizadas por las tiendas y compañías de suministro. Especialmente para organizar sus inventarios. También, pueden verse a menudo en supermercados y farmacias. Como características, podemos describir que las Bases de Datos dinámicas, a diferencias de otras, sí permiten modificar, actualizar o eliminar los datos que contienen a medida que pasa el tiempo. Por eso es normal que muchos especialistas subrayen como atributo destacado su flexibilidad.
También podemos decir que son bases de datos relacionales, en el sentido de que constantemente se establecen relaciones entre los registros y sus campos. De todas maneras, hay que decir que su principal función sigue siendo la de guardar información. ¿Qué tipo de información? Especialmente, aquella que puede cambiar con el tiempo.
Como desventajas podríamos comentar que las bases de datos dinámicas son más complejas de mantener, ya que deben ir actualizándose todo el tiempo. A diferencia de otras, aquí es más frecuente encontrarse con datos inexactos, erróneos o incompletos. Tampoco son prácticas para hacer estudios de variables a lo largo del tiempo o análisis de Business Intelligence.

Base de datos estáticas
Al respecto, expertos en el ámbito de la gestión de datos explican que a diferencia de las bases anteriores descritas, éstas suelen utilizarse con el objetivo de almacenar y registrar datos históricos. Por eso encontrarán que en diferentes portales la describen como una base de datos de “solo lectura”. ¿Qué significa esto? Que los datos no pueden ser editados o modificados luego de ingresar. Ahí radica su rasgo distintivo.
Al utilizarse una Base de datos estática, la idea es poder establecer un análisis de los datos ingresados a lo largo del tiempo (en base a su comportamiento), de modo tal que la empresa, institución o persona interesada pueda pueda sacar conclusiones en base a lo observado. Aquellas organizaciones que desean realizar proyecciones estadísticas y orientar los procesos de toma de decisiones desde el ámbito empresarial, deben saber que este tipo de base de datos puede ser su mejor aliado.
Como desventaja podemos marcar aquí que, a diferencia de las “Dinámicas”, son bastante inflexibles. Por otro lado, los datos utilizados suelen ser muy concretos y no tienen un rango de utilización muy general. Esto también es algo a tener en cuenta. De todas maneras, sus ventajas o desventajas siempre irán de la mano del uso que se le termine dando. Por eso es clave que, previamente, la empresa u organización en cuestión haga un reconocimiento de lo que realmente necesita.
Base de datos jerárquicas
Estas pueden ser definidas como un modelo de datos donde éstos se almacenan en forma de registros y se organizan en una estructura parecida a un árbol, donde un nodo principal (el 0 es el principal y el más importante de todos) puede tener muchos nodos secundarios a través de enlaces. Es ideal para gestionar grandes volúmenes de datos.
Bajando a tierra el concepto, una base de datos jerárquica es aquella que permite almacenar información (como las nombradas anteriormente), solo que en ésta los datos se organizan de forma jerárquica. Es decir, según su relevancia. Para que lo visualicen concretamente, a continuación les dejaremos un pequeño gráfico, donde pueden observar claramente cómo adquiere la forma de un árbol invertido.
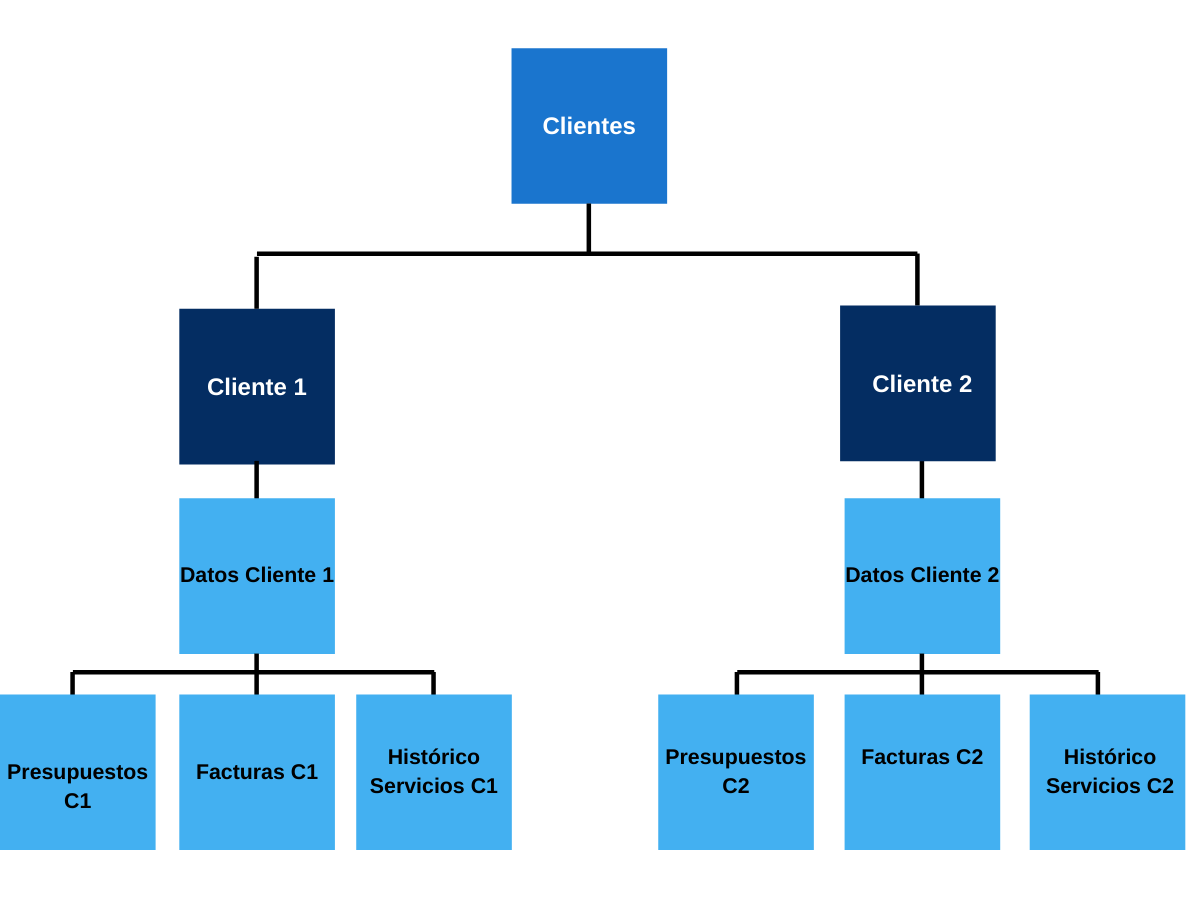
Entre las ventajas que presentan podemos reconocer el hecho de que la navegación por éstas es verdaderamente rápida. Esto se debe a que las conexiones dentro del árbol son fijas. Además de su velocidad, también es sencilla de ver y comprender. Por otro lado, permiten que cualquier usuario pueda acceder a esta información. Por eso muchos expertos hablan de que las bases de datos jerárquicas globalizan la información.
Yendo a lado de sus desventajas, según el diccionario tecnológico Technopedia, los modelos de bases de datos jerárquicos son útiles para cierto tipo de almacenamiento de datos, pero no se caracterizan por ser versátiles. Por desgracia, están limitados a algunos usos muy específicos.
“Los modelos jerárquicos tienen más sentido cuando el enfoque principal de la recopilación de información está en una jerarquía concreta, como una lista de departamentos comerciales, activos o personas que se asociarán con elementos de datos primarios específicos de nivel superior”, señalan.
Un ejemplo concreto para aplicar una base de datos jerárquica puede ser una empresa que brinda servicios de Internet y quiere organizar sus clientes. Servicios, facturas, presupuestos, datos.
Bases de datos relacionales
El tipo de base de datos más extendido es, sin duda, el basado en el “modelo relacional”, en el que las distintas entidades se representan en forma de tabla, se conectan entre sí a través de las llamadas “relaciones” y se modelan, actualizan, consultan y eliminan mediante uno de los lenguajes informáticos más populares del mundo, el “Structured Query Language” (también conocido por las siglas SQL).
Entre las principales características del modelo relacional se encuentran el uso de “claves primarias”, utilizadas para identificar de forma exclusiva cada fila de una tabla, “claves foráneas”, que relacionan dos o más tablas garantizando el respeto de la restricción de integridad referencial, y “índices” que facilitan las actividades de búsqueda mediante “consultas sql” (también conocidas como “query”).
Para entender mejor el significado de estos principios, consideremos el caso de una pequeña empresa que necesita recibir y procesar pedidos de sus productos.
En este contexto, es posible identificar dos tablas simples que contienen información sobre los clientes y los pedidos recibidos, respectivamente.
Como es fácil adivinar, cada registro de la tabla “cliente” puede incluir datos como un identificador único (que representa la “clave primaria”), el nombre, la dirección, la información de envío y facturación, el número de teléfono, etc., mientras que en la tabla “pedido”, cada fila puede incluir el identificador del cliente que hizo la solicitud, el producto pedido, la cantidad, la talla y el color seleccionados.
En el ejemplo anterior, está claro que los clientes y los pedidos pueden correlacionarse a través de la columna “ID_USUARIO” que asociará de forma única a una persona con un pedido recibido por la empresa de referencia.
Proyectando el razonamiento sobre un conjunto muy grande de tablas, filas y correlaciones y suponiendo una base de datos poblada de datos e información, es posible imaginar una base de datos relacional como una gran red en la que todas las entidades están conectadas de alguna manera, participando en la descripción de fenómenos complejos y están implicadas en las fases de almacenamiento, extrapolación, modificación, supresión, análisis de datos e interpolación de datos e información, lo que permite obtener una imagen completa y real de los fenómenos de referencia.
Bases de datos no relacionales
Una de las principales limitaciones relacionadas con las bases de datos relacionales está representada por la necesidad de reconstruir, mediante una serie de consultas y concatenaciones sucesivas, la información necesaria respecto a un caso concreto.
Retomando el sencillo ejemplo propuesto anteriormente, si una empresa quisiera conocer todos los pedidos enviados por un cliente concreto, necesariamente extrapolaría los datos de las tablas, los agregaría de la forma más adecuada, les asignaría un formato y los insertaría en un archivo, un documento o una presentación para compartirlos internamente (por ejemplo, durante las reuniones de la organización) o con interlocutores externos.
Para superar esta dificultad, que se hace cada vez más actual junto con la evolución de las plataformas “sociales” en las que la representación gráfica y la rapidez a la hora de compartir es de fundamental importancia, se han extendido en los últimos años algunos tipos de bases de datos no conectadas a esquemas relacionales y clasificadas, en general, como “no relacionales” o “noSql” (el acrónimo deriva de la locución inglesa Not Only SQL), ya que no pueden ser consultadas con el lenguaje basado en consultas tradicionales.

Otras base de datos
Bases de datos orientadas a objetos
Este modelo de base de datos está pensado para almacenar datos en forma de “objetos”, siguiendo los principios de la programación orientada a objetos. Cada objeto combina datos y funciones que permiten manipular esos datos, lo que facilita una relación directa con lenguajes como Java, Python o C++. Esto hace que sean una excelente opción para desarrolladores que trabajan en entornos complejos, como sistemas multimedia o de ingeniería avanzada.
Una de sus ventajas es la posibilidad de reutilizar código y aprovechar características como la herencia o el encapsulamiento. Como contrapartida, pueden volverse complejas de administrar y no siempre son compatibles con otros tipos de bases más tradicionales.
Bases de datos en red
A diferencia de las jerárquicas, este modelo permite que un nodo secundario dependa de varios nodos principales. Así, se pueden establecer relaciones más complejas. Su estructura flexible resulta útil en contextos donde la interconexión de datos es clave.
Aunque hoy se usan menos por la aparición de modelos más modernos, todavía mantienen relevancia en sistemas heredados o en escenarios donde hace falta representar redes complejas de información. De todos modos, su mantenimiento puede ser complicado y difícil de entender para quienes no conocen bien su lógica.
Bases de datos en memoria
Estas bases de datos guardan la información directamente en la memoria RAM, en lugar de hacerlo en discos duros o SSD. ¿El resultado? Muchísima más velocidad de procesamiento. Por eso se usan en situaciones donde el tiempo de respuesta tiene que ser casi inmediato, como en sistemas financieros, videojuegos online o plataformas de monitoreo.
Entre sus desventajas, sobresale la fuerte dependencia de la memoria disponible y, en general, su costo. Además, si no se configuran con mecanismos adecuados de persistencia, pueden perder datos.
Bases de datos distribuidas
En este tipo de base, los datos se reparten entre varias ubicaciones físicas, ya sea en servidores locales o en la nube. Sin embargo, para quien la usa, todo funciona como si fuera una única base coherente.
Son una buena opción cuando se necesita escalar, garantizar disponibilidad continua y resistir fallos. Su complejidad técnica es alta porque hay que manejar la sincronización y la consistencia entre distintos nodos. Aun así, los beneficios en rendimiento y capacidad de expansión justifican su uso en sistemas actuales.
Bases de datos de series temporales
Este tipo de base está pensada para manejar datos que cambian con el tiempo. En vez de enfocarse en entidades y relaciones, se concentra en registrar eventos de manera secuencial. Por eso es ideal para guardar valores como temperaturas, precios de acciones, métricas de rendimiento o lecturas de sensores.
Su mayor ventaja es que permite gestionar y consultar grandes volúmenes de datos cronológicos con eficiencia. Se usan mucho en sistemas IoT, análisis financiero, salud y plataformas de monitoreo industrial.
Los principales tipos de bases de datos noSQL
Partiendo de que la familia de bases de datos noSQL incluye un conjunto tan amplio y diverso de soluciones que no existe una forma única de clasificarlas, acá se describen cuatro grandes grupos de bases no relacionales que hoy tienen mucho uso:
Bases de datos orientadas a documentos
Representan los datos mediante entidades sin un esquema fijo, conocidas como documentos. Cada unidad puede tener atributos que se agregan o modifican con el tiempo, de manera flexible, para reflejar distintos aspectos de la información que se quiere guardar o procesar.
Por ejemplo, una entidad como “persona” puede estar representada por un documento con datos personales básicos. Con el tiempo, ese mismo documento puede sumar información sobre su profesión, gustos culinarios u otros detalles, sin las limitaciones típicas de una base relacional.
Bases de datos clave/valor
Funcionan a partir de una estructura lógica muy común en el desarrollo de software: la “hash table” o diccionario. Se trata de pares formados por una clave y un valor. En pocas palabras, la información se vincula a una clave que permite buscarla de forma simple y rápida.
Bases de datos gráficas
Este tipo de base usa una estructura muy conocida en ingeniería de software: el grafo. Se parece a una red donde distintos nodos se conectan entre sí mediante arcos.
Un ejemplo típico es el de las redes sociales. En ese contexto, dos usuarios que son “amigos” se representan como nodos unidos por un arco. Esa conexión permite, por ejemplo, sugerir nuevos contactos a un usuario al recorrer el grafo y detectar vínculos de segundo grado.
Bases de datos en memoria
Este tipo de base aprovecha el uso de memorias volátiles, como la RAM, para ofrecer un rendimiento muy alto y permitir que las aplicaciones o los usuarios accedan a los datos casi en tiempo real.
En estos casos, es clave contar con mecanismos que combinen la velocidad de la memoria con la necesidad de mantener y guardar la información en el tiempo. Así se asegura que los datos puedan recuperarse incluso mucho después de haber sido generados.
Tipos de bases de datos NoSQL
| Tipo de base de datos | Descripción | Ejemplo / Analogía |
|---|---|---|
| Bases de datos orientadas a documentos | Representan los datos mediante documentos sin un esquema fijo. Los atributos pueden agregarse o modificarse con el tiempo, lo que brinda gran flexibilidad. | Documento de una persona que puede ampliarse con datos como profesión o gustos personales. |
| Bases de datos clave/valor | Utilizan una estructura de pares clave-valor, similar a un diccionario o hash table. Permiten búsquedas muy rápidas y simples a partir de la clave. | Diccionario donde cada palabra (clave) tiene su definición (valor). |
| Bases de datos gráficas | Organizan los datos en grafos, con nodos (entidades) conectados por arcos (relaciones). Son ideales para representar relaciones complejas entre elementos. | Red social donde los usuarios (nodos) están conectados por relaciones de amistad (arcos). |
| Bases de datos en memoria | Almacenan datos en la memoria RAM para ofrecer acceso ultrarrápido. Requieren mecanismos que aseguren la persistencia de los datos a largo plazo. | Aplicaciones en tiempo real que necesitan velocidad, como sistemas de trading o monitoreo de sensores. |
Las diferencias entre las bases de datos relacionales y no relacionales
En general, la mayor diferencia entre las bases de datos tradicionales y las no relacionales está en que estas últimas no usan estructuras lógicas como las tablas. En su lugar, utilizan otros formatos de almacenamiento, como documentos, que permiten reunir y ofrecer de forma inmediata todos los datos vinculados a una entidad específica cuando se los necesita.
Modelado en bases de datos relacionales
Para entender mejor las diferencias entre los dos tipos de bases de datos, se puede analizar un ejemplo concreto: el modelado de una base de datos orientada a la gestión de artículos científicos, que suelen incluir datos como el autor, la revista en la que se publica, la fecha de publicación, entre otros.
En una base de datos relacional, hay que identificar y distribuir cada uno de estos elementos en distintas tablas. Así, en este caso, se generarían al menos tres tablas: una para los artículos —con columnas como “idArtículo” y “título”—, otra para los autores —con “idAutor”, “nombre” y “apellido”—, y otra para las revistas científicas —que incluiría, por ejemplo, “idRevista” y “nombre”—. Además, habría que definir las relaciones necesarias para vincular cada artículo con sus autores y con la revista en la que fue publicado.
Este modelo permite guardar la menor cantidad de datos posible, ya que evita repeticiones. Sin embargo, cuando se necesita acceder a la información completa de una publicación, hace falta reconstruirla a partir de varias tablas, lo cual puede ser engorroso y llevar tiempo.
Modelado en bases de datos no relacionales (NoSQL)
En una base de datos NoSQL basada en documentos, el registro de un artículo suele guardarse como un único documento, generalmente en formato JSON. A diferencia de las bases relacionales, donde la información se reparte entre varias tablas, acá todos los datos vinculados a un mismo artículo —como el autor, la revista, el título y la fecha de publicación— se almacenan como atributos dentro de una sola entidad.
Esto permite acceder de forma rápida y directa a toda la información relacionada con una publicación, sin necesidad de hacer múltiples consultas ni reconstrucciones complejas.
Casos ideales para bases de datos NoSQL
A partir de lo anterior, queda claro que las bases de datos NoSQL resultan muy adecuadas para sistemas como los juegos, los servicios online o las apps móviles que necesitan bases de datos flexibles, escalables y rápidas, con un buen nivel de rendimiento y funcionalidad para garantizar una buena experiencia de uso.
Las ventajas de las bases de datos no relacionales
- Reducción de la carga computacional: Las bases de datos no relacionales, al no requerir operaciones complejas de agregación, permiten evitar muchos de los límites de procesamiento que sí afectan a los entornos SQL. En estos últimos, la velocidad de las consultas disminuye a medida que crece el tamaño de la base, la cantidad de tablas y el volumen de información que hay que escribir, modificar o borrar. Por eso, las bases de datos NoSQL se adaptan bien a sistemas que manejan grandes volúmenes de datos y donde el tiempo de respuesta resulta clave.
- Independencia respecto a un esquema rígido: a diferencia de las bases de datos relacionales tradicionales, que están sujetas a esquemas fijos que determinan la estructura de las tablas y sus relaciones, las bases de datos NoSQL permiten manejar distintos tipos de información con mucha más flexibilidad. No requieren una estructura predeterminada, lo que las hace más dinámicas y adaptables frente a cambios o datos poco estructurados.
- Mayor “escalabilidad horizontal“: gracias a que permiten organizar los datos en estructuras basadas en archivos y no dependen de un esquema definido de antemano, las bases de datos no relacionales ofrecen ventajas importantes en términos de escalabilidad horizontal. Esto significa que es posible mejorar el rendimiento al sumar nuevos contenedores de datos, que pueden operar de forma simultánea sin generar cuellos de botella.
Tabla: Ventajas de las bases de datos no relacionales (NoSQL)
| Ventaja | Descripción |
|---|---|
| Reducción de la carga computacional | Al evitar operaciones complejas como las agregaciones propias de SQL, ofrecen un mejor rendimiento en sistemas con grandes volúmenes de datos y alta demanda de velocidad de respuesta. |
| Independencia de esquemas rígidos | No requieren estructuras fijas como las bases de datos relacionales. Se adaptan fácilmente a diferentes tipos de información, incluso si están poco estructurados o cambian con el tiempo. |
| Mayor escalabilidad horizontal | Permiten distribuir los datos en múltiples contenedores que funcionan en paralelo, mejorando el rendimiento sin generar cuellos de botella y facilitando el crecimiento del sistema. |
Tipos de software de bases de datos y DBMS empresariales: los mejores, características y cuál elegir
Una vez planteado el panorama general y explicadas las principales diferencias entre las bases de datos clásicas —basadas en SQL— y las de nueva generación —sin esquemas relacionales—, vale la pena revisar cuáles son las soluciones más usadas en las empresas. También es importante identificar algunos criterios simples que puedan servir para elegir la base de datos más adecuada, según las necesidades específicas de cada organización o frente a las exigencias que impone el mercado.
MySQL
El DBMS relacional más extendido y utilizado en el mundo es probablemente “MySQL“, que es una solución de código abierto, de uso libre y adquirida, gracias a su creciente popularidad, por un gigante de las bases de datos como Oracle, que incluso incorpora algunas características en su DBMS comercial.
Uno de los puntos fuertes de MySQL es que puede utilizarse, a través de una serie de conectores desarrollados a lo largo del tiempo por su amplia comunidad de desarrolladores, en los principales lenguajes de programación, como Java, Php, Dotnet, Pyton, etc.
Otra ventaja de MySQL, que lo convierte en un DMBS ideal para un gran número de empresas, es que puede instalarse tanto en sistemas operativos Windows como Linux/Uninx.
Entre las limitaciones que generalmente se le imputan a este DBMS, en cambio, es posible registrar una compatibilidad no completa con el SQL estándar, una gestión no perfecta de los accesos concurrentes a la base de datos y, por último, la presencia de herramientas limitadas para las búsquedas de “texto completo”, útiles sobre todo en caso de textos largos.
Servidor SQL
No podía faltar un producto de Microsoft en la lista de los DBMS más populares y utilizados en las librerías corporativas: desde su creación, de hecho, SQL Server ha encontrado inmediatamente un buen éxito gracias a la plena integración con otras herramientas proporcionadas por la empresa de Redmond (pensemos por ejemplo en el entorno de desarrollo “Visual Studio”, el framework .Net, etc.).
Entre los puntos fuertes de SQL Server, además de la plena compatibilidad con SQL, se encuentra la amplia gama de licencias que van desde las completamente gratuitas como Express (limitada a 4 núcleos, 1 GB de RAM por instancia y 10 GB de capacidad de BD) y Developer (utilizable sólo en entornos de desarrollo) hasta las de pago, más complejas y elaboradas, como Web, Standard y Enterprise.
Es necesario, sin embargo, subrayar cómo SQL Server no es totalmente compatible con sistemas operativos distintos al de Microsoft: si, de hecho, es posible instalarlo también en algunas distribuciones de Linux, de la documentación oficial se desprende que algunas funciones sólo están garantizadas en entornos Windows.
PostgresSQL
PostgresSQL se considera un estándar universal de referencia para todas aquellas situaciones en las que es necesario gestionar no sólo los clásicos caracteres alfanuméricos (como letras, números, caracteres especiales, etc.), sino también datos de naturaleza compleja, como los datos georreferenciados, o los relativos a contenidos multimedia.
Este DBMS, de hecho, amplía con éxito el modelo relacional tradicional al incluir enfoques típicos de la programación orientada a objetos como la herencia, las clases, la encapsulación, que permiten gestionar escenarios típicamente difíciles para los DBMS tradicionales como los relacionados con el seguimiento espacial, la gestión de archivos de vídeo, audio, etc.
Se trata, en efecto, de una solución extremadamente madura, gracias a sus más de 30 años de presencia en el mercado, completamente opensource y capaz de garantizar el cumplimiento casi total del estándar SQL, pero también de soportar el lenguaje “JSON”, típico de las bases de datos no relacionales.
Entre los puntos débiles cabe mencionar una baja velocidad de lectura, en parte relacionada con las propiedades particulares de los datos gestionados, la documentación a veces incompleta y disponible sólo en inglés y un número limitado de plataformas de alojamiento en las que es realmente posible utilizar postgresSQL.
Mongodb
En la galaxia cada vez más vasta y variada de las bases de datos noSQL, un lugar de prestigio lo ocupa sin duda MongoDB, que está disfrutando de un extraordinario y repentino éxito gracias a la elección hecha por gigantes de la web como Facebook y Twitter de utilizarla como plataforma de referencia para la gestión de sus vastos activos de información.
En pocas palabras, MongoDB puede definirse como una “base de datos orientada a documentos” (o en lenguaje anglosajón “document-oriented storage database”) porque, como se ha mencionado anteriormente, la unidad básica de agregación y almacenamiento de datos es el documento, compuesto por una serie de campos de longitud dinámica que pueden almacenar información de naturaleza compleja.
Entre las características más apreciadas de MongoDb destacan, en particular, la posibilidad de dotar a cualquier atributo de un “índice” que puede agilizar las búsquedas, y la sencillez con la que la base de datos puede distribuirse en un gran número de servidores independientemente de su ubicación geográfica.
Por estas razones, MongoDB se utiliza cada vez más en entornos en los que es necesario almacenar y poner en línea grandes volúmenes de información en intervalos de tiempo extremadamente restringidos.
MongoDB, gracias a una excelente integración con los lenguajes de programación más comunes para la web como PHP, Python y Ruby, se presta a ser utilizado de forma extremadamente sencilla tanto en proyectos destinados a la reconversión de sistemas que operan sobre bases de datos relacionales como para nuevas aplicaciones web basadas originalmente en el DBMS nosql.
Sap/HANA
Un elemento muy innovador en el mundo de las bases de datos lo representa la plataforma HANA (High-performance Analytic Appliance) de SAP que, aprovechando las características de la “computación en memoria”, pretende garantizar el tratamiento de grandes volúmenes de datos operativos y transaccionales en tiempo real. En extrema síntesis, HANA pretende integrar los sistemas de gestión utilizados por la mayoría de las empresas medianas y grandes con bases de datos extremadamente rápidas capaces de apoyar las decisiones estratégicas mediante la producción inmediata de informes, índices y “business cases” especialmente detallados.
Se trata, de hecho, de una solución articulada y estratificada que también permite agregar e importar información de fuentes externas y heterogéneas (como las bases de datos tradicionales, pero también las redes sociales, los archivos de texto, etc.), realizando, por tanto, también las funciones típicamente asociadas al “almacén de datos” y, en consecuencia, permitiendo a las organizaciones adquirir nuevos conocimientos a través del análisis y la concatenación de datos previamente dispersos en bases de datos diferentes e inconexas.
Otra innovación introducida por HANA consiste en la posibilidad de utilizar directamente a nivel empresarial las ventajas derivadas del “Big data” gracias a la capacidad de procesar grandes cantidades de información mediante la aplicación efectiva de técnicas de business intelligence y data minning a los activos de información de cada organización.
Por lo tanto, es inmediatamente comprensible cómo la solución propuesta por SAP supera los límites dentro de los cuales operan generalmente las bases de datos para abarcar temas y áreas más amplias, capaces de garantizar una gestión “holística” de la información de la empresa y extraer valor de los datos almacenados y archivados en tiempos y formas que serían impensables con las técnicas clásicas o tradicionales.
Oracle/Timesten
Cuando se habla de bases de datos, ciertamente no es posible ignorar a un coloso como Oracle, que ha construido su reputación proporcionando herramientas, software y aplicaciones que pueden gestionar bases de datos de considerable tamaño y criticidad con eficiencia, extraordinaria eficacia y altos niveles de seguridad.
A lo largo de los años, los DBMS y las soluciones distribuidas por la empresa estadounidense, que ha ido ampliando sus áreas de actuación hasta abarcar todo el espectro de las tecnologías de la información, han alcanzado un éxito increíble hasta convertirse casi en un estándar de facto.
Entre los productos más innovadores lanzados por Oracle en los últimos años, cabe destacar Timesten, que se encuentra en el espacio de la base de datos “In Memory” y que, como se ha mencionado anteriormente en relación con Hana, permite obtener un rendimiento impensable hasta hace poco tanto en la fase de búsqueda de datos, como en la extracción de informes y documentos estratégicos destinados a apoyar al gobierno de las organizaciones tanto públicas como privadas.
| DBMS | Tipo | Ventajas principales | Limitaciones / Consideraciones |
|---|---|---|---|
| MySQL | Relacional (SQL) – Open Source | Muy utilizado, gratuito, multiplataforma (Windows/Linux), compatible con muchos lenguajes de programación. | No 100% compatible con SQL estándar, manejo limitado de accesos concurrentes, búsquedas de texto completo básicas. |
| SQL Server | Relacional (SQL) – Microsoft | Integración total con herramientas Microsoft (.NET, Visual Studio), variedad de licencias (gratuitas y comerciales). | Funciona mejor en Windows; en Linux tiene funciones limitadas. |
| PostgreSQL | Relacional (SQL) – Open Source | Potente para datos complejos (multimedia, geodatos), soporte de objetos, compatible con JSON, muy maduro. | Lectura lenta en algunos casos, documentación en inglés, menos opciones de hosting. |
| MongoDB | No relacional (NoSQL – Documentos) | Flexible, escalable, ideal para grandes volúmenes de datos, buena integración web (PHP, Python, Ruby), búsquedas rápidas. | Menos adecuado para datos muy estructurados o con relaciones complejas. |
| SAP HANA | In-Memory + Analítica avanzada | Procesamiento en tiempo real, integración de datos heterogéneos, ideal para Big Data y BI empresarial. | Costosa, compleja, pensada para grandes organizaciones. |
| Oracle / TimesTen | Relacional e In-Memory (SQL) | Alto rendimiento, seguridad avanzada, soluciones para entornos críticos, estándar de facto en muchas industrias. | Requiere inversión alta, complejidad de gestión, licencias propietarias. |
Otras soluciones de base de datos utilizadas en empresas
MariaDB
Entre las alternativas más consistentes a MySQL, se destaca MariaDB. Es una solución de código abierto que mantiene total compatibilidad con su antecesor, aunque desde su creación avanzó con un ritmo propio y más ágil.
La comunidad original de desarrolladores de MySQL impulsó este proyecto, que incorporó mejoras importantes en rendimiento y seguridad, además de respetar con mayor precisión el estándar SQL.
Este sistema de gestión de bases de datos incluye motores de almacenamiento avanzados, optimizaciones en la replicación y una flexibilidad superior para contextos de alta exigencia técnica. Por todo esto, MariaDB gana terreno como una opción confiable para quienes buscan continuidad, pero también una evolución tecnológica concreta.
IBM Db2
Es la propuesta de la empresa para la gestión de datos en contextos de misión crítica. Es un sistema de gestión de bases de datos relacional sólido, muy utilizado por sectores clave como la banca, los seguros y el comercio.
Su punto fuerte es una arquitectura consolidada, con funciones avanzadas para comprimir datos, manejar grandes volúmenes de información e integrarse con sistemas heredados.
Db2 soporta tanto cargas transaccionales como analíticas, lo que lo vuelve una plataforma híbrida pensada para organizaciones de gran escala que priorizan la estabilidad, la escalabilidad y el rendimiento.
Cassandra
Dentro del universo de las bases de datos NoSQL, Apache Cassandra se posicionó como una de las opciones más confiables para aplicaciones que necesitan escalar a gran escala y mantenerse siempre disponibles. Su arquitectura descentralizada permite distribuir datos en miles de nodos sin depender de un punto único de fallo, lo que la vuelve ideal para servicios globales como los de Netflix o Uber.
Cassandra maneja grandes volúmenes de datos estructurados con eficacia y asegura una baja latencia tanto en lectura como en escritura, incluso bajo alta demanda. Es una herramienta clave para empresas que trabajan en tiempo real y con múltiples usuarios activos al mismo tiempo.
Redis
Redis nació como una herramienta de caché, pero con el tiempo se transformó en una base de datos en memoria de uso general, orientada a estructuras clave-valor. Su velocidad en las operaciones de lectura y escritura la hace ideal para sistemas que necesitan respuestas en milisegundos, como plataformas financieras, videojuegos online o servicios de mensajería en tiempo real.
Redis también ofrece funciones como pub/sub, listas, conjuntos y scripts en Lua, lo que facilita su uso en arquitecturas complejas. Su adopción creció por la demanda de bases de datos livianas y potentes.
Couchbase
En el mundo de las bases de datos NoSQL, Couchbase se destaca por combinar un modelo documental flexible con las ventajas del almacenamiento clave-valor y una arquitectura distribuida que resiste fallos. Desde su creación apuntó a ofrecer alto rendimiento, disponibilidad constante y sincronización offline, lo que la hace especialmente útil en apps móviles y contextos con múltiples usuarios activos.
Couchbase permite escalar horizontalmente casi sin límites, mantiene la coherencia de los datos y responde con rapidez. Por eso, cada vez más empresas la consideran una alternativa real a MongoDB en desarrollos nuevos.
ClickHouse
Es una base de datos pensada para organizaciones que procesan volúmenes enormes de información con fines analíticos. La desarrolló Yandex y está orientada a columnas, lo que le permite ejecutar consultas OLAP con una velocidad difícil de igualar.
Su estructura columnar y su capacidad para comprimir datos la vuelven ideal para análisis web, monitoreo de sistemas o inteligencia de negocios. Ofrece un rendimiento que antes solo se lograba con infraestructuras complejas y caras, pero lo hace con una propuesta open source y escalable.
DuckDB
Cuando el procesamiento de datos necesita ser local, rápido y sin depender de una infraestructura pesada, DuckDB aparece como una base de datos analítica embebida en memoria. Fue diseñada como una especie de “SQLite para análisis” y permite ejecutar consultas SQL complejas directamente desde notebooks, entornos de ciencia de datos o apps, sin servidores externos. Aunque es liviana, ofrece un rendimiento notable en tareas analíticas, sobre todo cuando se trabaja con archivos locales como CSV o Parquet. Por eso, gana cada vez más espacio en contextos de análisis ágil y exploratorio.
Amazon Aurora
Es la propuesta de Amazon Web Services para quienes necesitan bases de datos relacionales en la nube con alto rendimiento y baja latencia. Es compatible con MySQL y PostgreSQL, pero suma mejoras en disponibilidad, replicación automática, respaldo continuo y recuperación instantánea. Su arquitectura separa el procesamiento de los datos, lo que permite escalar cada parte según la demanda del sistema. Es una opción atractiva para empresas que ya trabajan en AWS y buscan una base de datos gestionada, eficiente y segura.
Neo4j
Es la base de datos más usada en el mundo de los grafos. A diferencia de los modelos relacionales o documentales, permite mapear y consultar relaciones complejas entre entidades de forma directa. Por eso, es ideal para sistemas de recomendación, detección de fraudes, redes sociales o análisis de vínculos.
Su lenguaje de consulta, Cypher, facilita la identificación de patrones dentro de los datos y ofrece una mirada distinta para descubrir conexiones que no siempre son visibles. Así, las empresas pueden sacarle más provecho a la información relacional que manejan.
El impacto de las base de datos en las decisiones estratégicas
Las bases de datos dejaron de ser herramientas de almacenamiento para convertirse en estructuras que moldean decisiones. El modo en que una empresa accede, organiza y analiza su información influye directamente en sus movimientos estratégicos, tanto a nivel operativo como comercial.
Cuando el diseño de un producto, la segmentación de clientes o la evaluación financiera depende de sistemas que recopilan millones de datos, el impacto no es menor. La calidad de esas decisiones depende en buena medida de lo que se hace con la información disponible.
Información estructurada como insumo estratégico
Las empresas que entienden el valor de su información interna sacan ventaja en cada área del negocio. Una base de datos bien estructurada permite anticipar demandas, reducir costos, detectar errores y optimizar recursos. Pero para eso no alcanza con almacenar: hace falta procesar, interpretar y actuar.
Ese es el punto donde el análisis de datos deja de ser una tarea técnica y empieza a jugar en el plano estratégico. Las organizaciones que no cruzan esa frontera quedan atadas a decisiones impulsivas, sin respaldo estadístico ni evidencia concreta.
Impacto en sectores sensibles
En estos casos, lo que parece técnico roza lo YMYL, porque el análisis mal hecho puede traducirse en pérdidas económicas, fallas en la producción o problemas legales. Y todo eso nace del modo en que una base de datos fue diseñada o consultada.
La mala gestión de datos en una empresa también puede derivar en consecuencias graves. Por ejemplo, un error en la base de datos de una compañía de alimentos puede llevar a una distribución equivocada, o a decisiones comerciales que impacten en el precio final de productos esenciales.
Decisiones que dependen de los datos
Cuando una empresa decide abrir una nueva sucursal, modificar su logística o invertir en tecnología, muchas veces lo hace guiada por reportes internos. Esos reportes surgen de la información recolectada a lo largo del tiempo. Si la base de datos es débil, la estrategia puede fallar.
Por eso, trabajar sobre la calidad de los datos ya no es una tarea de soporte, sino parte del núcleo central de la empresa. No se trata solo de tener mucha información, sino de que sea precisa, relevante y esté organizada con lógica.
Bases sólidas, decisiones más firmes
En un escenario donde cada movimiento puede significar ganancias o pérdidas en millones de US$, las decisiones respaldadas por datos bien gestionados tienen más chances de funcionar. Las empresas que invierten en bases sólidas no solo optimizan sus recursos: también toman decisiones más firmes, con menos margen de error.
FAQs: pregungas frecuentes sobre base de datos
¿Cómo seleccionar el tipo de base de datos ideal según el modelo de negocio de una empresa TIC?
La elección depende del volumen de datos, la necesidad de escalabilidad, la estructura de la información (relacional o no) y los requisitos de disponibilidad. Evaluar estos factores permite alinear la base de datos con los objetivos de negocio y la arquitectura tecnológica.
¿Qué impacto tiene la adopción de bases de datos NoSQL en la arquitectura de microservicios?
Las bases de datos NoSQL permiten una mayor flexibilidad y escalabilidad horizontal, lo que las hace ideales para arquitecturas de microservicios que requieren independencia entre servicios y procesamiento distribuido.
¿Cuáles son las mejores prácticas para migrar de bases de datos on-premise a soluciones cloud-native?
Es clave realizar una evaluación de compatibilidad, definir una estrategia de replicación y establecer políticas de seguridad y respaldo. Herramientas como AWS DMS o Azure Database Migration Service facilitan este proceso.
¿Qué indicadores clave de rendimiento (KPIs) se deben monitorear en una estrategia de gestión de bases de datos empresariales?
Los KPIs críticos incluyen el tiempo de respuesta de consultas, tasa de errores, disponibilidad del sistema y costos operativos. Monitorear estos datos optimiza el rendimiento y asegura la continuidad del negocio.




